当 AI 开始改进 AI:RSI 的工程现实与对齐难题
2026-07-06
递归自我改进(RSI)从 AI 安全社区的思想实验变成了有 ICLR workshop、有数十亿美元融资、有可量化进展曲线的系统工程问题。这篇文章从历史脉络出发,梳理 autoresearch 如何逐步逼近 RSI、当前技术进展的实际位置,以及对齐误差在递归中的复利效应。
6454 字
|
32 分钟
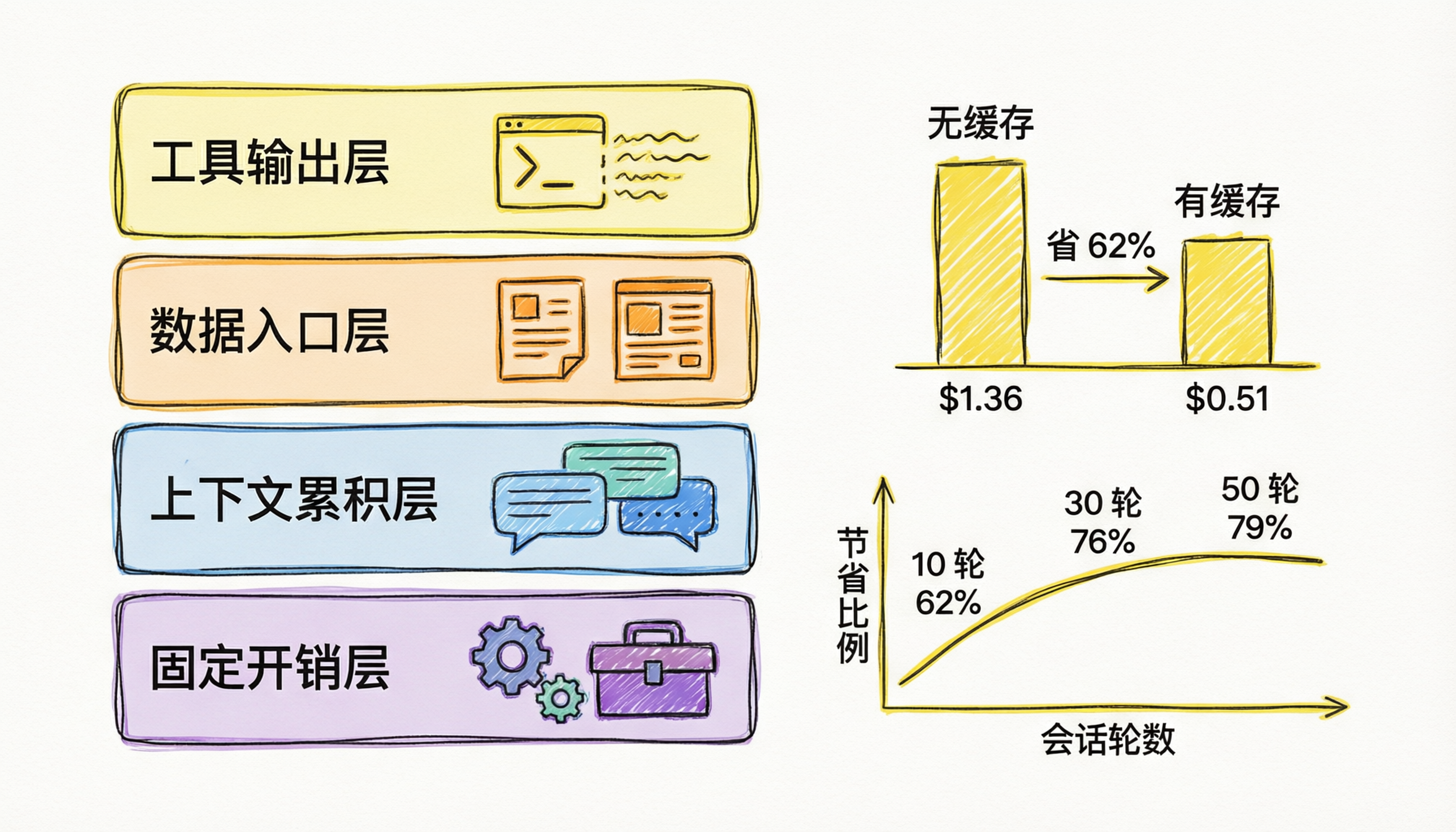
用了一天 Claude Code,20 美元花在哪里
2026-05-26
用了一天 Claude Code,账单比你想象的高?把 token 消耗按来源拆开看,你输入的字 + 模型生成的字加起来不到 20%,剩下 80% 是你压根没注意到的东西。这篇文章拆清楚钱花在哪四个地方、每处能不能省、以及具体能省多少。
7609 字
|
38 分钟
Test-Time Compute:让模型在回答之前先想一想
2026-05-25
训练阶段的算力扩展正在撞墙,一个新方向浮出水面:与其把模型训得更大,不如让它在回答时多想一会儿。从学术源头到四家厂商的工业实现,这篇文章讲的是推理时间的算力经济学。
3942 字
|
20 分钟

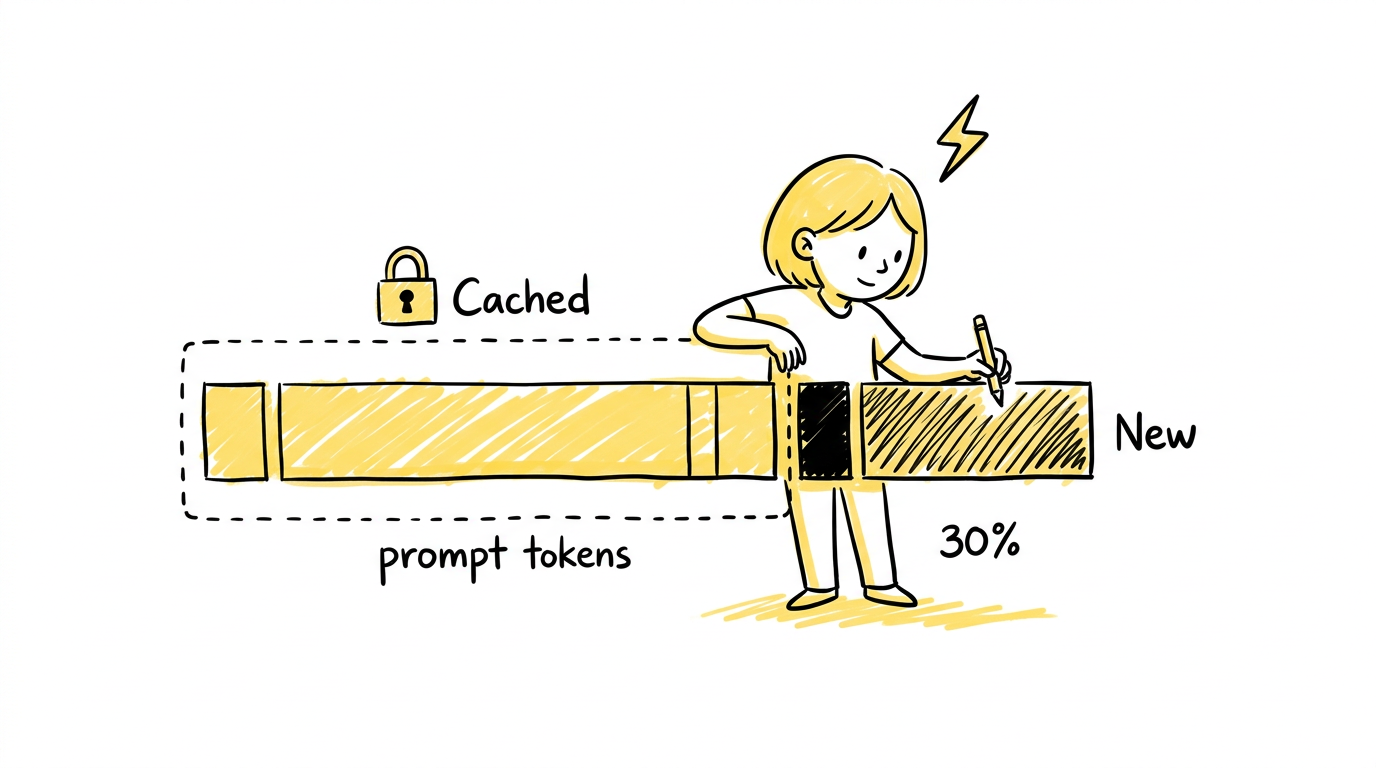
Prompt Caching:被忽视的非对称性
2026-05-18
Prompt Caching 不是省钱的开关,而是对 LLM 推理成本结构的一次重新理解。从 KV Cache 的物理基础到三家厂商的设计哲学,再到工程实践的几条原则——一篇关于'重复计算就是浪费算力'的文章。
4897 字
|
24 分钟
2026 重读 Lilian Weng:Agent 的三年与那张未老的地图
2026-05-18
2023 年 6 月,Lilian Weng 写下了「LLM Powered Autonomous Agents」。三年后重读,99% 的 AI 文章已成废墟,这篇不是——她画下的地图,至今还在指引方向。
2375 字
|
12 分钟
Ralph Loop:让 AI 编程 Agent 通宵干活的自主循环范式
2026-05-13
你还在一轮一轮地给 AI 发指令?Ralph Loop 用一个 while true 循环加 Stop Hook,让 Claude Code 和 Codex CLI 变成了可以连续工作十几个小时的自主 Agent。这篇文章从原理到实操,拆解这个正在重塑 AI 编程工作流的范式。
3876 字
|
19 分钟

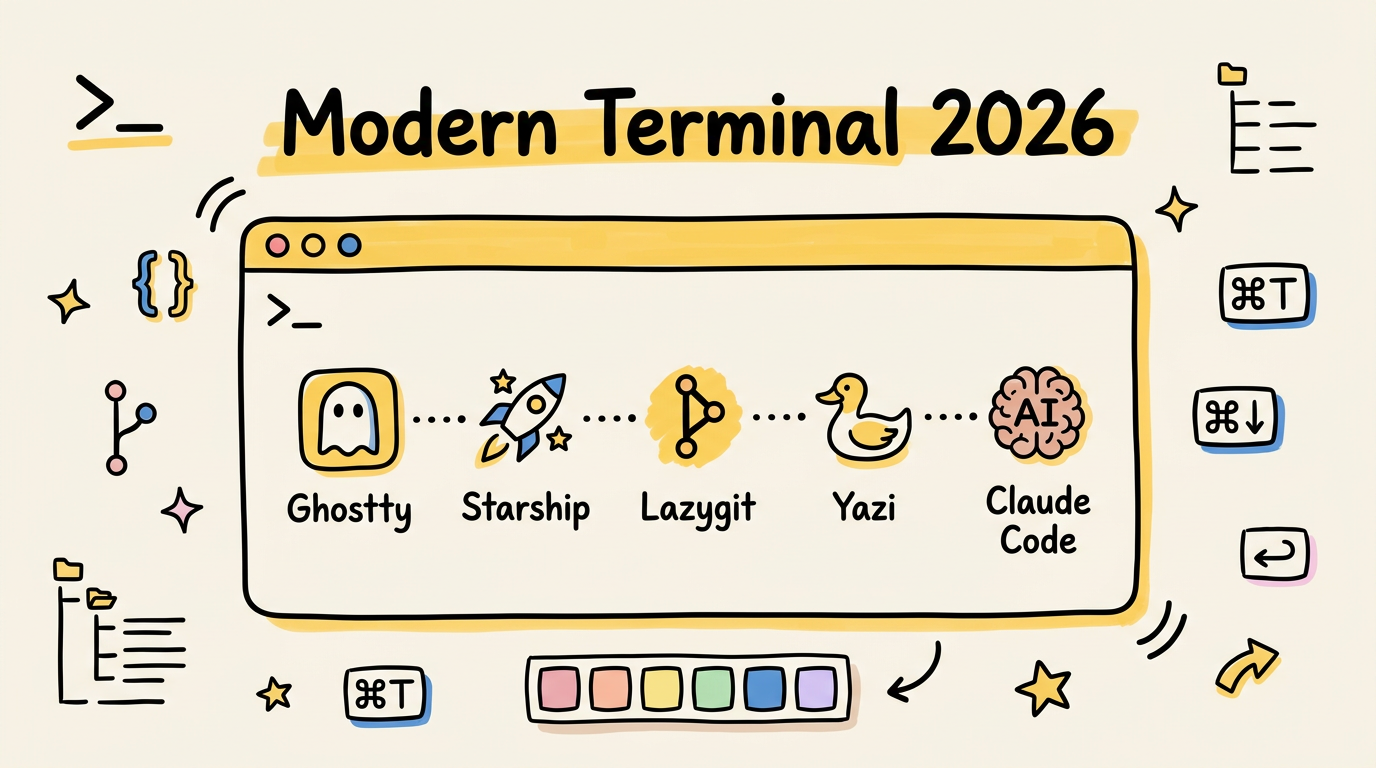
我的 2026 终端方案:Ghostty + Starship + Lazygit + Yazi + Claude Code
2026-05-06
折腾终端这件事,本质上是在回答一个问题:日常开发中,你的手指在哪些操作上浪费了最多时间?这篇文章分享我当前的终端工具链——Ghostty 做渲染、Starship 做 prompt、Lazygit 管 Git、Yazi 管文件、Claude Code 做 AI 辅助——以及它们如何拼成一个流畅的工作流。
3175 字
|
16 分钟
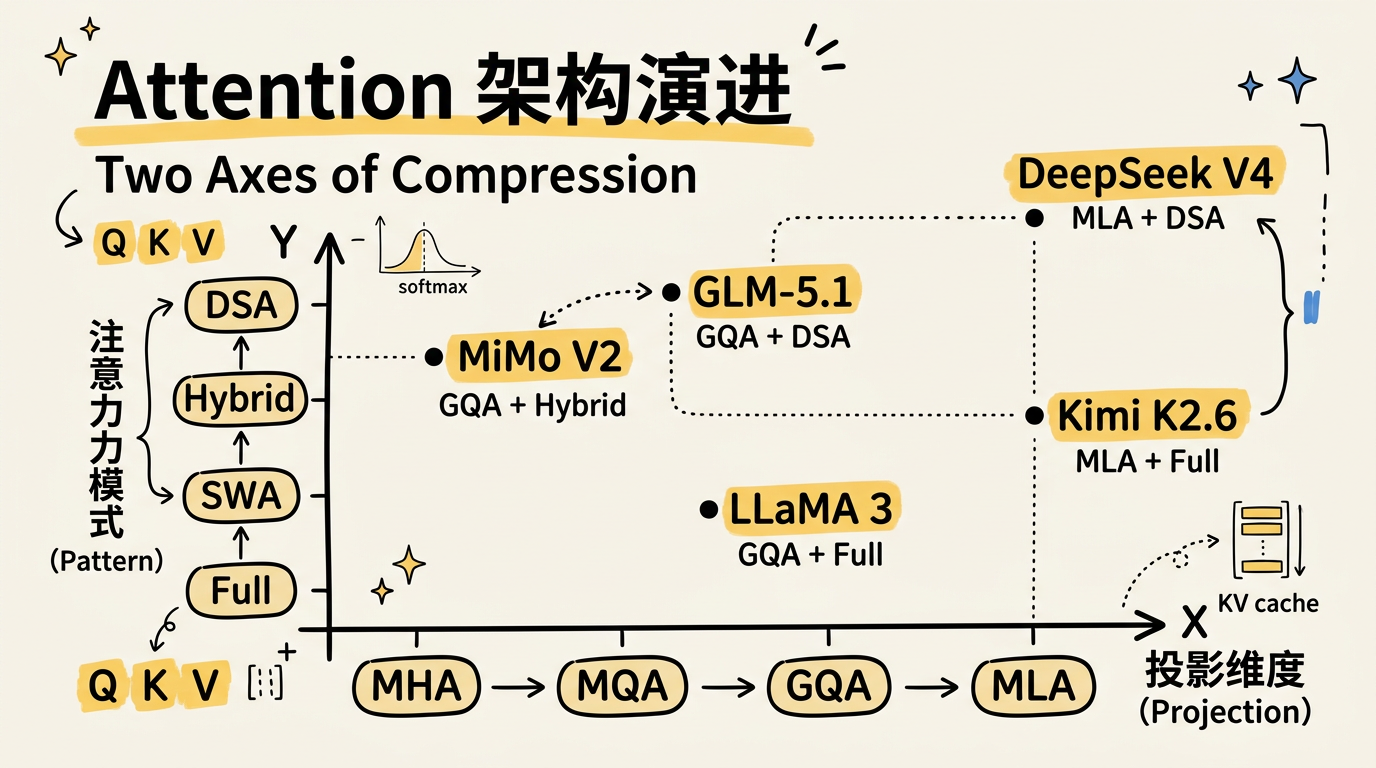
Attention 架构演进:从 MHA 到 MLA,一场关于 KV Cache 的战争
2026-04-29
标准 Attention 有两个可优化的自由度:KV 投影的特征维度,和每个 query 关注的序列范围。九年间,MQA、GQA、MLA 沿第一条轴将 KV Cache 压缩了 57 倍;SWA、NSA、DSA 沿第二条轴将注意力计算从 O(n) 降到 O(k)。2026 年,DeepSeek V4、MiMo V2、GLM-5.1、Kimi K2.6 在两条轴上做出了截然不同的选择。本文从数学公式出发,沿这两条轴线梳理完整脉络。
3265 字
|
16 分钟