
基于word2vec的红楼梦人物关系分析
word2vec是Google公司在2013年提出的一种词嵌入算法。使用word2vec算法对词汇进行向量化后,原来的近义词在向量空间中是邻近的,因此word2vec可以很好的保留原来词汇之间的相似性。
本文使用gensim库实现的word2vec算法,对红楼梦中的人物关系进行分析,得到了许多有趣的结论。
获取文本
首先我们需要获取原著的本文文件,并且需要保证文本文件足够「纯净」,可以减少文本处理的工作量。
可以通过爬虫,从http://www.purepen.com获取原始文本。
爬虫代码如下:
1 | import requests |
代码中通过sleep机制简单的避免了被反爬。
文本处理
首先需要使用正则表达式将所有的标点符号去掉。红楼梦属于半白话文半文言文的问题,因此其中许多词语分词系统是不能识别的,但是因为我们这次做的只是人物关系,所以只需要把所有的人名写入用户字典就可以保证所有的人名都能被准确地识别出来。
1 | def segment(): |
按道理应该是要去掉停用词的,不过我不想做,偷个懒。😛
模型训练
使用gensim实现的word2vec算法进行向量化,因为文本不是很大,所以向量长度我选择的200,window大小选择的3。
1 | def train_model(): |
训练起来还是很快的,大概一秒钟就好了。
PCA降维
因为原始的向量长度太大,所以我们可以先用PCA(主成分分析)将向量降到二维,然后在坐标系中画出来。
1 | from gensim.models import word2vec |
因为word2vec会忽略掉频次比较小的词语,所以我们在获取词向量时需要进行异常捕捉。
让我们看一下效果吧!
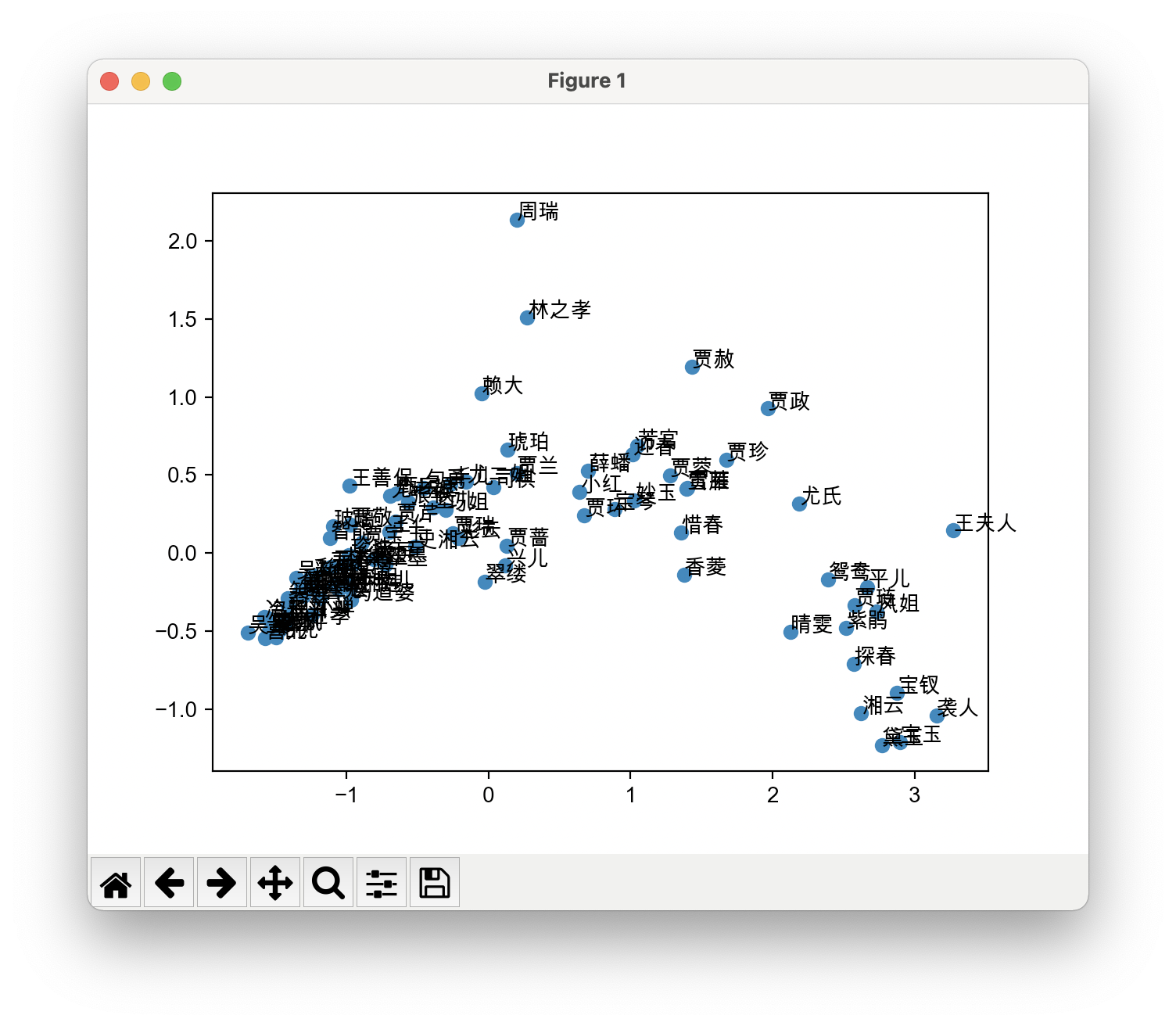
因为名字有点多,整体看起来有点拥挤。我们把焦点放在又下角,可以看到宝黛钗三个人都在,我们放大一下。
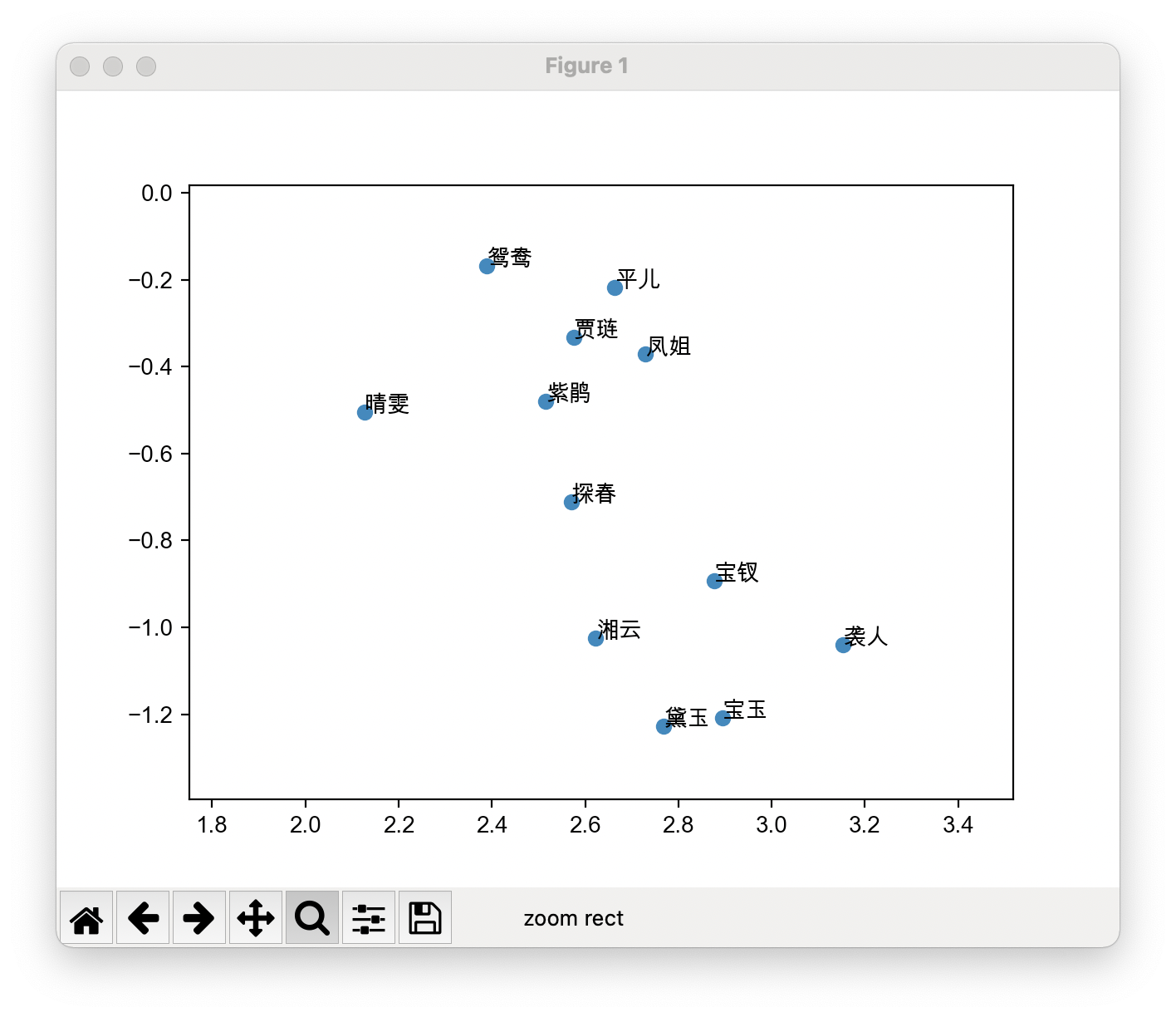
我们可以看到宝玉和黛玉紧紧挨着一起,宝黛一生吹好吧!
最相似分析
word2vec中提供了几个有趣的方法,我们可以用这些方法进一步分析一下人物关系。
代码如下:
1 | from gensim.models import word2vec |
结果如下:
1 | Nearest 宝玉: [('黛玉', 0.9654377102851868), ('袭人', 0.9432756304740906), ('贾琏', 0.9404013156890869), ('紫鹃', 0.9312815070152283), ('晴雯', 0.9278832674026489), ('鸳鸯', 0.9248123168945312), ('湘云', 0.9108842015266418), ('凤姐', 0.9095652103424072), ('宝钗', 0.9087227582931519), ('薛姨妈', 0.9083631634712219)] |
从上面的结果可以看到,宝玉最相似的是黛玉,黛玉最相似的是宝玉,而宝钗最相似的是探春。
并且可以看到「宝玉」和「黛玉」的相似度比「贾宝玉」和「黛玉」的相似度更高,说明在文中前者往往是成对出现的。
另外,我们还得到了两个有趣的式子:
$$
宝玉 - 宝钗 + 黛玉 \approx 宝玉
$$
$$
宝玉 - 黛玉 + 宝钗 \approx 贾琏
$$
很有意思😂
基于word2vec的红楼梦人物关系分析



