Softmax function# Softmax function is used to regularize all number of a vector to [0, 1]. It is usual appeared in classification problems. By softmax, a vector with huge number can be projected to a small number range — from 0 to 1. That is useful to avoid gradient explosion & vanishing.
The formula of softmax as follows:
z = [ z 1 , z 2 , ⋯ , z n ] a = softmax ( z ) = [ e z 1 ∑ e z k , e z 2 ∑ e z k , ⋯ , e z n ∑ e z k ] z = [z_1, z_2, \cdots, z_n] \\\\
a = \text{softmax}(z) = [\frac{e^{z_1}}{\sum{e^{z_k}}}, \frac{e^{z_2}}{\sum{e^{z_k}}}, \cdots, \frac{e^{z_n}}{\sum{e^{z_k}}}] z = [ z 1 , z 2 , ⋯ , z n ] a = softmax ( z ) = [ ∑ e z k e z 1 , ∑ e z k e z 2 , ⋯ , ∑ e z k e z n ] By the way, softmax function is considered as a high-dimension generalization of sigmoid function and sigmoid function is also cansidered as a 2-dim version of softmax function. The formula of sigmoid as follows:
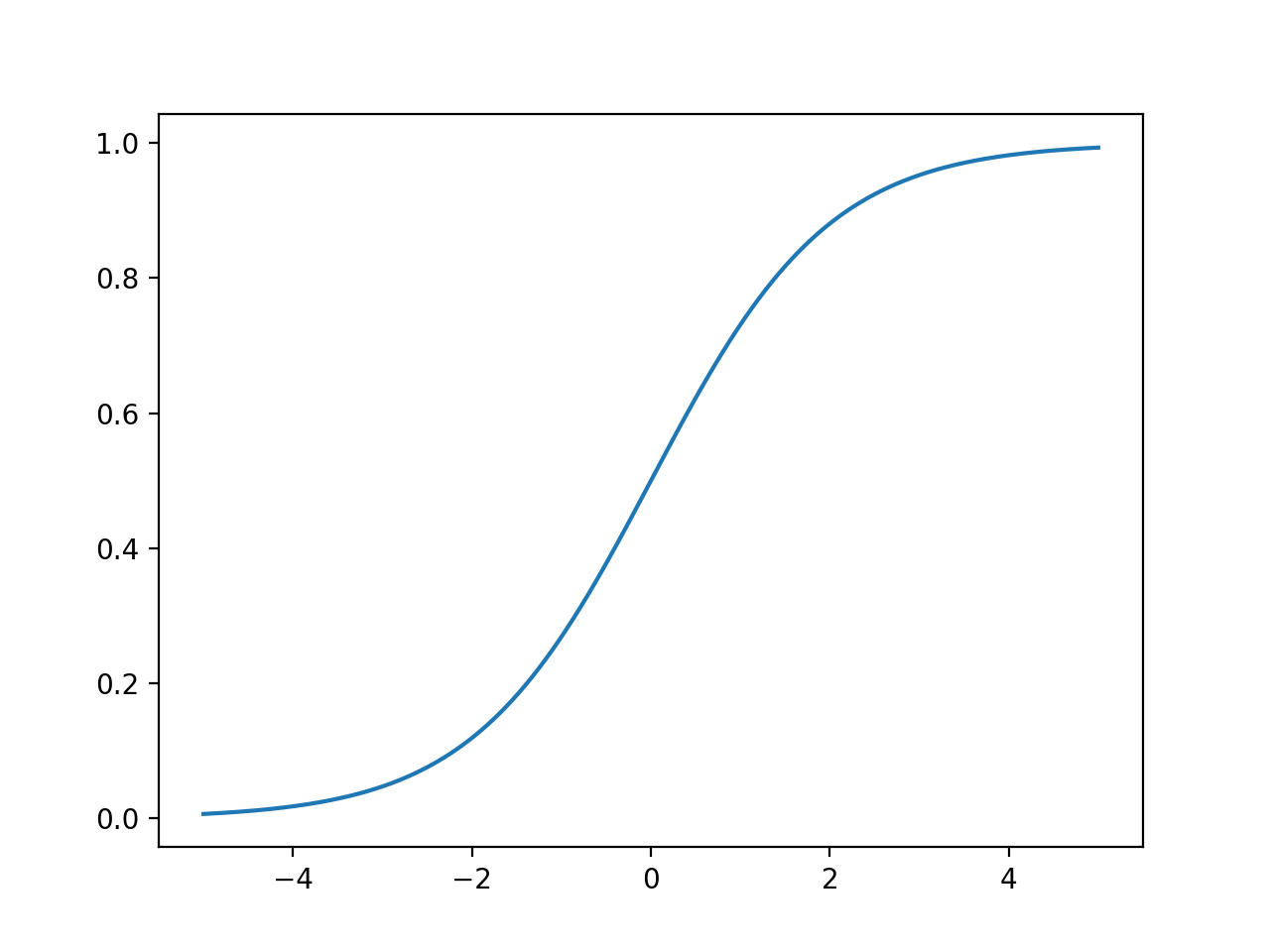
σ ( x ) = 1 1 + e − x \sigma(x) = \frac{1}{1+e^{-x}} σ ( x ) = 1 + e − x 1
Cross entropy# The cross-entropy of two probability distribution p p p q q q
H ( p , q ) = − ∑ p i log q i H(p, q) = -\sum p_i\log q_i H ( p , q ) = − ∑ p i log q i In classification problems, p p p
H ( p , q ) = − p k log q k = − log q k H(p, q)=-p_k\log q_k = -\log q_k H ( p , q ) = − p k log q k = − log q k We also use cross-entropy as loss function. It is very intuitive because, with the increase or decrease of q k q_k q k
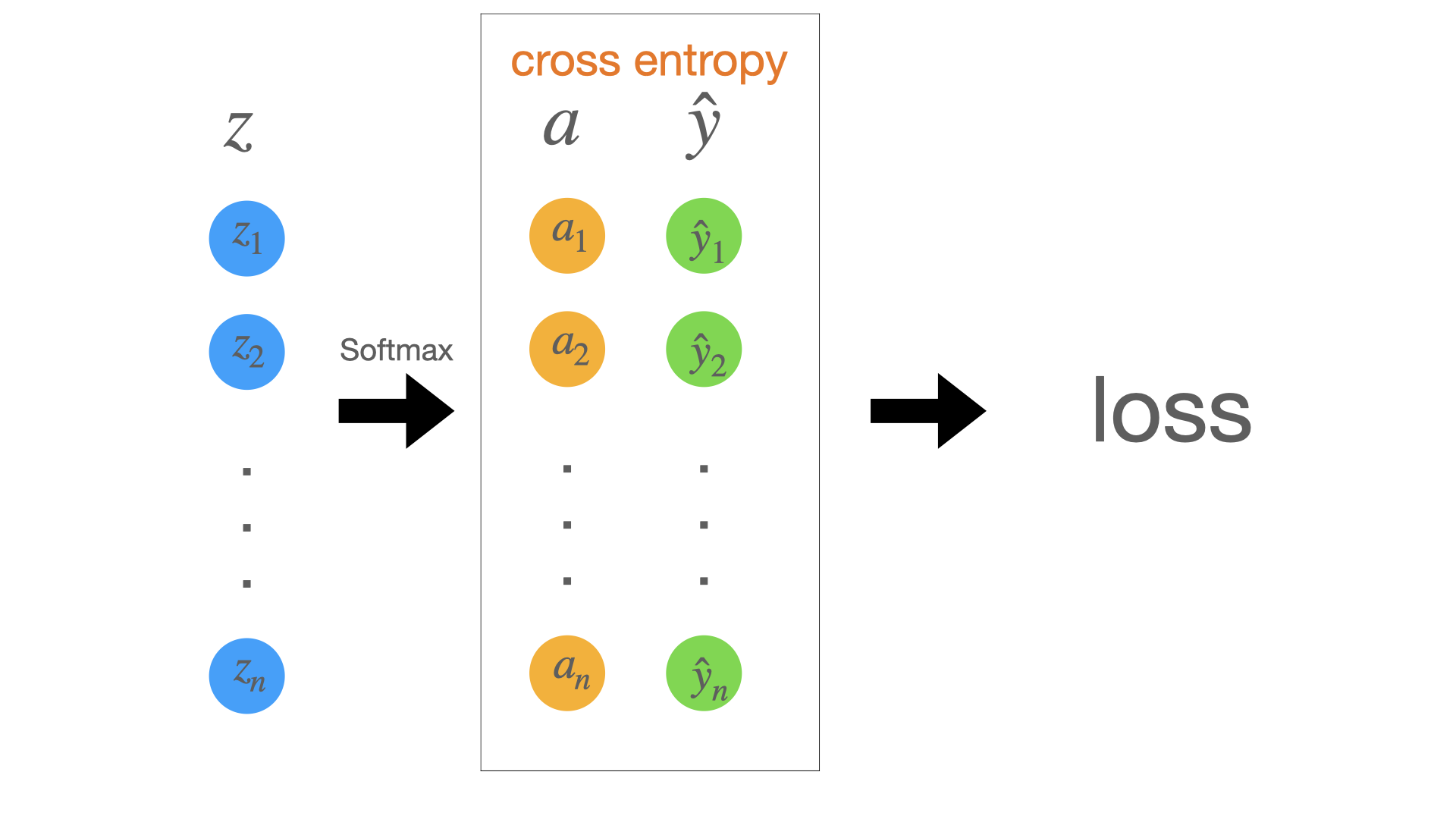
Calculate the derivative of loss function# The simplest classification network as follows:
Here z z z a a a z z z y ^ \hat y y ^ l o s s loss l oss a a a y ^ \hat y y ^
The formulas as follows:
l o s s = cross entropy ( a , y ^ ) = cross entropy ( softmax ( z ) , y ^ ) \begin{equation}
\begin{split}
loss
& = \text{cross entropy}(a, \hat y)\\
& = \text{cross entropy}(\text{softmax}(z), \hat y)
\end{split}
\end{equation} l oss = cross entropy ( a , y ^ ) = cross entropy ( softmax ( z ) , y ^ ) In order to make backpropagation, we need to calculate the deviation of l o s s loss l oss
∂ l ∂ z = ∂ l ∂ a ∂ a ∂ z \begin{equation}
\begin{split}
\frac{\partial l}{\partial \mathbf z}
& = \frac{\partial l}{\partial \mathbf a}\frac{\partial \mathbf a}{\partial \mathbf z}
\end{split}
\end{equation} ∂ z ∂ l = ∂ a ∂ l ∂ z ∂ a Here l l l a a a z z z
First, we need to know how to calculate the derivative of a scalar y y y x x x
∂ y ∂ x = [ ∂ y ∂ x 1 , ∂ y ∂ x 2 , ⋯ , ∂ y ∂ x n ] \frac{\partial y}{\partial \mathbf x} = [\frac{\partial y}{\partial x_1},\frac{\partial y}{\partial x_2},\cdots, \frac{\partial y}{\partial x_n}] ∂ x ∂ y = [ ∂ x 1 ∂ y , ∂ x 2 ∂ y , ⋯ , ∂ x n ∂ y ] Second, how to calculate the derivative of a vector y y y x x x
∂ y ∂ x = [ ∂ y 1 ∂ x ∂ y 2 ∂ x ⋮ ∂ y n ∂ x ] \frac{\partial \mathbf y}{\partial x} =\begin{bmatrix}\frac{\partial y_1}{\partial x} \\\\ \frac{\partial y_2}{\partial x}\\\\ \vdots \\\\ \frac{\partial y_n}{\partial x}\end{bmatrix} ∂ x ∂ y = ∂ x ∂ y 1 ∂ x ∂ y 2 ⋮ ∂ x ∂ y n And, how to calculate the derivative of a vector y y y x x x
∂ y ∂ x = [ ∂ y 1 ∂ x 1 ∂ y 1 ∂ x 2 ⋯ ∂ y 1 ∂ x n ∂ y 2 ∂ x 1 ∂ y 2 ∂ x 2 ⋯ ∂ y 2 ∂ x n ⋮ ⋮ ⋱ ⋮ ∂ y n ∂ x 1 ∂ y n ∂ x 2 ⋯ ∂ y n ∂ x n ] \frac{\partial \mathbf y}{\partial \mathbf x} =
\begin{bmatrix}
\frac{\partial y_1}{\partial x_1} & \frac{\partial y_1}{\partial x_2} & \cdots & \frac{\partial y_1}{\partial x_n}\\\\
\frac{\partial y_2}{\partial x_1} & \frac{\partial y_2}{\partial x_2} & \cdots & \frac{\partial y_2}{\partial x_n} \\\\
\vdots & \vdots & \ddots & \vdots \\\\
\frac{\partial y_n}{\partial x_1} & \frac{\partial y_n}{\partial x_2} & \cdots & \frac{\partial y_n}{\partial x_n}\end{bmatrix} ∂ x ∂ y = ∂ x 1 ∂ y 1 ∂ x 1 ∂ y 2 ⋮ ∂ x 1 ∂ y n ∂ x 2 ∂ y 1 ∂ x 2 ∂ y 2 ⋮ ∂ x 2 ∂ y n ⋯ ⋯ ⋱ ⋯ ∂ x n ∂ y 1 ∂ x n ∂ y 2 ⋮ ∂ x n ∂ y n We can infer the former two by the last one.
According to the above formula, we have this result as follows:
∂ l ∂ a = [ ∂ l ∂ a 1 , ∂ l ∂ a 2 , ⋯ , ∂ l ∂ a k , ⋯ , ∂ l ∂ a n ] = [ 0 , 0 , ⋯ , − 1 a k , ⋯ , 0 ] \begin{split}
\frac{\partial l}{\partial \mathbf a}
& = [\frac{\partial l}{\partial a_1},\frac{\partial l}{\partial a_2},\cdots, \frac{\partial l}{\partial a_k}, \cdots, \frac{\partial l}{\partial a_n}] \\\\
& = [0, 0, \cdots, -\frac{1}{a_k}, \cdots, 0]
\end{split} ∂ a ∂ l = [ ∂ a 1 ∂ l , ∂ a 2 ∂ l , ⋯ , ∂ a k ∂ l , ⋯ , ∂ a n ∂ l ] = [ 0 , 0 , ⋯ , − a k 1 , ⋯ , 0 ] ∂ a ∂ z = [ ∂ a 1 ∂ z 1 ∂ a 1 ∂ z 2 ⋯ ∂ a 1 ∂ z n ∂ a 2 ∂ z 1 ∂ a 2 ∂ z 2 ⋯ ∂ a 2 ∂ z n ⋮ ⋮ ⋱ ⋮ ∂ a n ∂ z 1 ∂ a n ∂ z 2 ⋯ ∂ a n ∂ z n ] \frac{\partial \mathbf a}{\partial \mathbf z} =
\begin{bmatrix}
\frac{\partial a_1}{\partial z_1} & \frac{\partial a_1}{\partial z_2} & \cdots & \frac{\partial a_1}{\partial z_n}\\\\
\frac{\partial a_2}{\partial z_1} & \frac{\partial a_2}{\partial z_2} & \cdots & \frac{\partial a_2}{\partial z_n} \\\\
\vdots & \vdots & \ddots & \vdots \\\\
\frac{\partial a_n}{\partial z_1} & \frac{\partial a_n}{\partial z_2} & \cdots & \frac{\partial a_n}{\partial z_n}\end{bmatrix} ∂ z ∂ a = ∂ z 1 ∂ a 1 ∂ z 1 ∂ a 2 ⋮ ∂ z 1 ∂ a n ∂ z 2 ∂ a 1 ∂ z 2 ∂ a 2 ⋮ ∂ z 2 ∂ a n ⋯ ⋯ ⋱ ⋯ ∂ z n ∂ a 1 ∂ z n ∂ a 2 ⋮ ∂ z n ∂ a n Furthermore, when i = j i = j i = j
∂ a i ∂ z j = ∂ e z i ∑ e z k ∂ z j = e z i ∑ e z k − e z i e z i ( ∑ e z k ) 2 = a i − a i 2 = a i ( 1 − a i ) \begin{split}
\frac{\partial a_i}{\partial z_j}
& = \frac{\partial \frac{e^{z_i}}{\sum{e^{z_k}}}}{\partial z_j} \\\\
& = \frac{e^{z_i}\sum e^{z_k} - e^{z_i}e^{z_i}}{(\sum e^{z_k})^2} \\\\
& = a_i - a_i^2 \\\\
& = a_i(1-a_i)
\end{split} ∂ z j ∂ a i = ∂ z j ∂ ∑ e z k e z i = ( ∑ e z k ) 2 e z i ∑ e z k − e z i e z i = a i − a i 2 = a i ( 1 − a i ) When i ≠ j i \neq j i = j
∂ a i ∂ z j = ∂ e z i ∑ e z k ∂ z j = 0 − e z i e z j ( ∑ e z k ) 2 = − a i a j \begin{split}
\frac{\partial a_i}{\partial z_j}
& = \frac{\partial \frac{e^{z_i}}{\sum{e^{z_k}}}}{\partial z_j} \\\\
& = \frac{0-e^{z_i}e^{z_j}}{(\sum{e^{z_k}})^2} \\\\
& = -a_ia_j
\end{split} ∂ z j ∂ a i = ∂ z j ∂ ∑ e z k e z i = ( ∑ e z k ) 2 0 − e z i e z j = − a i a j So,
∂ a ∂ z = [ a 1 ( 1 − a 1 ) − a 1 a 2 ⋯ − a 1 a n − a 2 a 1 a 2 ( 1 − a 2 ) ⋯ − a 2 a n ⋮ ⋮ ⋱ ⋮ − a n a 1 a n a 2 ⋯ a n ( 1 − a n ) ] \frac{\partial \mathbf a}{\partial \mathbf z} =
\begin{bmatrix}
a_1(1-a_1) & -a_1a_2 & \cdots & -a_1a_n\\\\
-a_2a_1 & a_2(1-a_2) & \cdots & -a_2a_n \\\\
\vdots & \vdots & \ddots & \vdots \\\\
-a_na_1 & a_na_2 & \cdots & a_n(1-a_n) \\\\
\end{bmatrix} ∂ z ∂ a = a 1 ( 1 − a 1 ) − a 2 a 1 ⋮ − a n a 1 − a 1 a 2 a 2 ( 1 − a 2 ) ⋮ a n a 2 ⋯ ⋯ ⋱ ⋯ − a 1 a n − a 2 a n ⋮ a n ( 1 − a n ) But actually, due to only ∂ l ∂ a k = − 1 a k \frac{\partial l}{\partial a_k} = -\frac{1}{a_k} ∂ a k ∂ l = − a k 1 ∂ a k ∂ z \frac{\partial a_k}{\partial \mathbf z} ∂ z ∂ a k
Finally, the derivative of l l l
∂ l ∂ z = ∂ l ∂ a ∂ a ∂ z = [ a 1 , a 2 , ⋯ , a k − 1 , ⋯ , a n ] = a − y \begin{equation}
\begin{split}
\frac{\partial l}{\partial \mathbf z}
& = \frac{\partial l}{\partial \mathbf a}\frac{\partial \mathbf a}{\partial \mathbf z} \\\\
& = [a_1, a_2, \cdots, a_k-1, \cdots, a_n] \\\\
& = \mathbf a - \mathbf y
\end{split}
\end{equation} ∂ z ∂ l = ∂ a ∂ l ∂ z ∂ a = [ a 1 , a 2 , ⋯ , a k − 1 , ⋯ , a n ] = a − y What a beautiful answer!
End.