引言:一个公式,两个自由度
Transformer 的核心是一行公式:
其中 分别由输入 经线性投影得到。在自回归推理时,每生成一个 token,模型需要缓存所有已生成 token 的 和 ——这就是 KV Cache。对于一个 32 层、32 头、head 维度 128 的模型,一个 4096 token 的上下文需要约 2 GB 的 KV Cache(FP16),而这只是一条请求。
过去九年,所有 Attention 架构创新都在优化这个公式的两个正交自由度:
自由度一:投影维度——、 的特征向量需要多宽?MHA 为每个头独立存储完整的 K、V;MQA 让所有头共享一份;GQA 分组共享;MLA 通过低秩投影将 KV 压到一个紧凑的潜在空间。这条线压缩的是 KV Cache 中每个 token 占多少字节。
自由度二:注意力模式——每个 query 需要关注多少个 token?标准 Attention 让每个 query 看完整序列( 个 token);SWA 只看最近 个;NSA/DSA 动态选出 top- 个最相关的。这条线压缩的是 KV Cache 中有多少 token 需要被读取,以及注意力计算本身的 FLOPs。
两条轴完全正交——一个压缩”宽度”,一个压缩”长度”——可以独立施加,也可以同时叠加。接下来沿两条轴线分别展开。
Part I 改投影:KV 的特征维度能压多低?
1. MHA:基线
给定输入 ,MHA 为 个头各自独立投影 Q、K、V:
其中 。每层参数量 (Q / K / V / 输出投影各 )。
KV Cache:每 token 每层缓存 个元素。以 GPT-3(,,,96 层)为例,每 token 合计约 4.5 MB(FP16),2048 token 上下文对应 9 GB。
FLOPs 为 (注意力矩阵)加 (投影)。上下文超过 后(GPT-3 约 12K token)二次项开始主导。2017–2022 年间 GPT 系列、BERT、PaLM 初版均使用标准 MHA,当时序列长度普遍在 2K–4K,KV Cache 尚未成为工程痛点。
2. MQA:极端共享
2019 年,Shazeer 提出 Multi-Query Attention:所有头共享同一组 K、V。
KV Cache 从 降到 ,压缩 倍(32 头即 32x)。代价是质量下降——从信息论角度看,MQA 迫使所有头通过同一个 KV 瓶颈获取信息:
当不同头需要的上下文模式差异较大时,单一 KV 的表达力不够。PaLM(540B)和 Falcon-180B 验证了 MQA 的吞吐优势,但在多跳推理任务上性能衰减明显。
3. GQA:分组折中
2023 年,Ainslie 等人提出 Grouped-Query Attention:将 个 Q 头分成 组,每组共享一套 K、V。
退化为 MHA, 退化为 MQA。KV Cache 为 ,压缩 倍。典型 压缩 4 倍,质量几乎无损。
消融实验表明 是最优区间,且从 7B 到 405B(LLaMA 3.1)都稳健——最优分组数似乎更多取决于 而非模型规模。GQA 论文还证明了现有 MHA checkpoint 可通过均值池化 K/V 投影 + 约 5% 继续训练转为 GQA,无需从头训练。自 LLaMA 2 起,Meta、Mistral AI、阿里巴巴 Qwen、Google Gemma 全线采用 GQA,使其成为 2023–2024 年的事实标准。
4. MLA:低秩压缩
2024 年,DeepSeek-V2 提出 Multi-head Latent Attention。不再减少 KV 头数,而是将所有头的 KV 联合投影到一个低维潜在空间。MQA/GQA 问”哪些头可以共享 KV?“,MLA 问”KV 的本征维度是多少?”
KV 联合压缩。将隐藏状态 投影到 维潜在向量,推理时只缓存它:
需要时通过上投影恢复:,。
解耦 RoPE。RoPE 逐元素应用,与低秩压缩不兼容——在压缩表示上施加 RoPE 会破坏推理时的矩阵吸收技巧。DeepSeek 将位置信息解耦为独立的低维位置键:
注意力分数因此分解为内容相关性与位置相关性两个独立分量:
矩阵吸收。内容注意力展开后:
推理时直接用低维潜在向量计算,无需恢复完整 K 矩阵。V 的上投影同理被吸收到输出投影中。
压缩效果。以 DeepSeek-V2(,,,)为例:
| 方法 | 每 token 每层缓存元素数 | 相对 MHA 压缩 |
|---|---|---|
| MHA | 1x | |
| GQA-8 | 16x | |
| MQA | 128x | |
| MLA | 57x |
压缩率介于 GQA 与 MQA 之间,但质量不降反升——低秩压缩充当正则化器,迫使模型学习更紧凑的表示。
产品验证。MLA 自 V2 起在 DeepSeek V2.5 / V3 / R1 / V4 全线沿用。月之暗面 Kimi K2 / K2.5 / K2.6(1T/32B,384 experts,61 layers,64 heads,)完整采用 MLA + MoE,参数配置与 DeepSeek-V3 高度同源,使 MLA 成为经多家独立验证的架构范式。TransMLA(2025)还证明可通过 SVD 分解现有 GQA 的 初始化 MLA 投影,以约 5% 继续训练量完成迁移。
Part I 小结
| 方案 | K/V 投影结构 | 每 token KV Cache | 年份 |
|---|---|---|---|
| MHA | 每头独立 | 2017 | |
| MQA | 全头共享 | 2019 | |
| GQA | 分组共享 | 2023 | |
| MLA | 联合低秩 | 2024 |
投影维度的压缩路径清晰:。但以上所有方案有一个共同假设——每个 query 都会读取全部 个 token 的 KV。当 达到 128K 乃至 1M 时,这个假设本身就值得质疑。
Part II 改模式:每个 query 需要看多少 token?
Part I 压缩了每个 token 的 KV 存储大小。但即使每个 token 的缓存已经很小,当 达到 1M 量级时,需要读取的 token 数量本身就是瓶颈——KV 总存储量 ,每步解码的 HBM 读取量 ,注意力 FLOPs 。
在进入架构改进之前,值得提一句 FlashAttention(Dao 等人, 2022–2024)。它不改变注意力的数学定义,通过分块计算和在线 softmax 将 HBM 读写量从 降到 ( 为 SRAM 大小),显存从 降到 ,是所有主流模型的通用基础设施。但它不改变 的 FLOPs——要突破这个上限,必须从架构上减少每个 query 实际关注的 token 数。
1. SWA:固定局部窗口
最直接的想法:每个 token 只关注最近 个 token。
KV Cache 变成固定大小的循环缓冲区,不随 增长。单层感受野为 , 层堆叠后理论感受野达 ——Mistral 7B(2023,32 层,)的理论感受野为 131K token。
纯 SWA 的局限在于底层只能看到局部上下文,全局信息必须经过多层逐步”传播”。Gemma 2(Google, 2024)率先引入混合策略:交替使用全局注意力层和 SWA 层。
2. Hybrid SWA + GA:周期性全局刷新
小米 MiMo-V2-Flash(309B/15B)和 MiMo-V2-Pro(1T+/42B)将混合策略推到极端。对第 层:
Flash 版 (每 6 层 5 层 SWA + 1 层 GA),Pro 版 。关键:窗口 token,远小于 Mistral 的 4096。这个极端窗口之所以可行,是因为 GA 层周期性地”刷新”全局信息,SWA 层只负责局部精细建模。
KV Cache。设模型 层,每层 KV 元素数 :
时 SWA 项可忽略,总 KV Cache 约为全注意力的 。Flash 版约 1/6,Pro 版约 1/8。值得注意的是 MiMo V2 没有使用 MLA——KV 压缩完全靠序列维度裁剪,与 Part I 的投影维度压缩正交,理论上可以叠加。
3. NSA:可学习的动态稀疏
固定窗口 SWA 的局限:窗口外的重要 token(如段首主题句)被无条件丢弃。2025 年,DeepSeek 的 Native Sparse Attention 让模型自己学会每个 query 应该关注哪些 token,将注意力分为三条并行路径:
- 压缩分支:将 token 块压缩为摘要表示(粗粒度全局信息)
- 选择分支:基于压缩分支评分选出 top- 相关 token(细粒度关键信息)
- 窗口分支:关注最近 个 token(局部上下文)
三路通过门控融合:
关键创新:所有分支(包括离散 token 选择)通过 straight-through 估计器实现端到端可微训练,不存在训练-推理不一致。NSA 获 ACL 2025 最佳论文。
4. DSA:NSA 的产品化与正交叠加
智谱 GLM-5/5.1(744B/~14B,78 层,256 routed experts + 1 shared,top-8 routing)直接将 NSA 思路部署为 Dynamic Sparse Attention。通过可学习的 indexer 矩阵做快速近似评分,选出每个 query 需要精确计算的子集:
为可学习 indexer, 为块级压缩 key。每个 query 的注意力计算从 降到 。GLM-5.1 是 DSA 在 750B 级上的首个生产验证,支撑 200K 上下文。
DeepSeek V4-Pro(1.6T/49B,61 层,384 experts + 1 shared)则展示了两条轴的正交叠加——在 MLA 的低秩 KV 上施加 DSA 的动态稀疏。MLA 压缩特征维度 ,DSA 压缩有效序列长度 ,两者同时生效。V4 还引入了 Engram Memory(一个 attention 之外的 hash-based 稀疏查找模块,将事实检索从 attention 路径中剥离),但这已超出注意力架构本身的范畴。
5. 算子变体:softmax 之外的探索
以上所有方案都保留了 softmax 作为注意力算子。少数工作尝试改变算子本身:
Differential Attention(微软,2024)将每个头的 Q、K 各分成两半,计算两个 softmax 注意力图的差值:
可学习。差分消除了不相关 token 的虚假注意力权重,论文报告约 65% 规模即可匹配标准 Transformer。
线性注意力用 替代 softmax,将复杂度从 降到 。MiniMax-M1(456B/46B)以 Lightning Attention 为核心架构,是线性注意力在超大规模上的最激进尝试。但后续 M2/M2.7 系列全面回退到标准 softmax attention——在推理和多轮对话中,线性注意力的精度严重崩坏。这个工业级教训是一个重要信号:attention 算子的表达力比理论效率更关键。
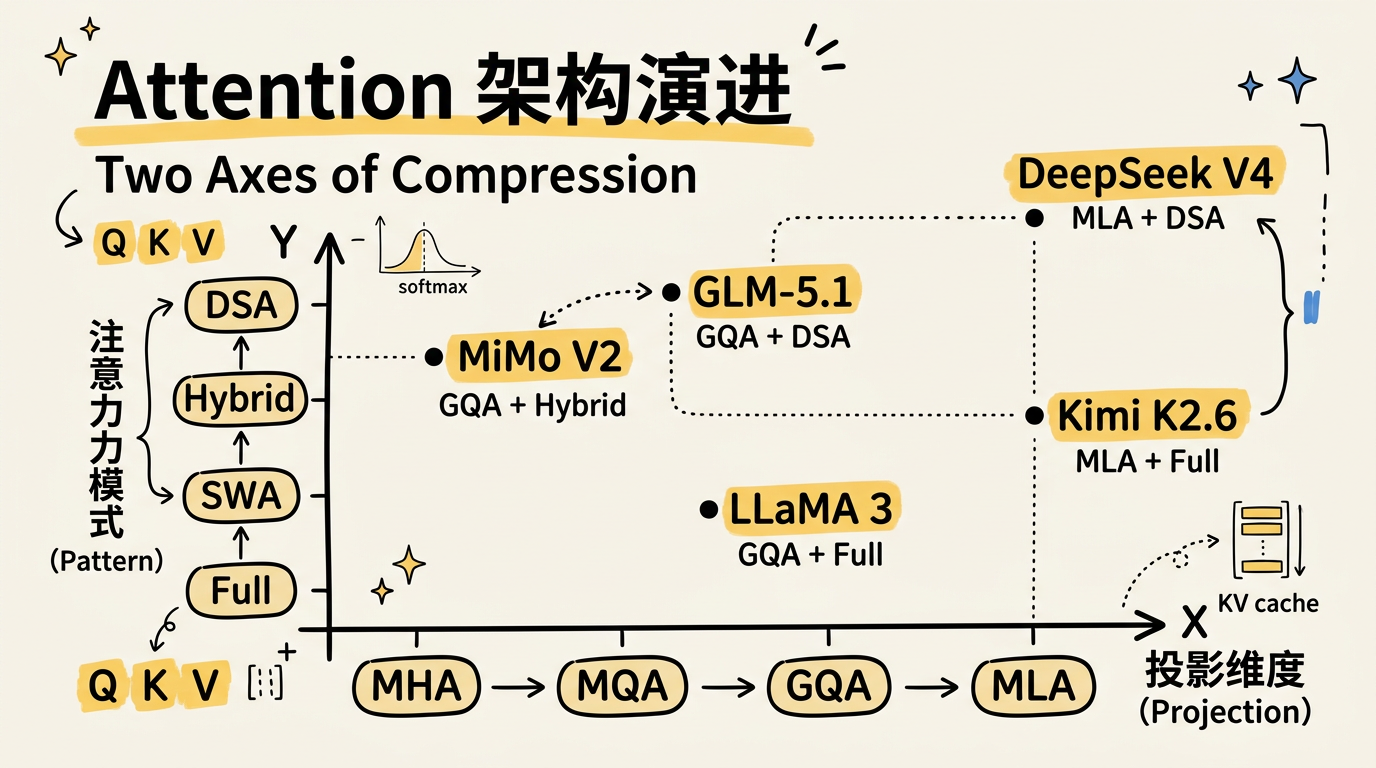
全景:两轴定位
将 2024–2026 主要产品模型定位到「投影 × 模式」二维空间:
| 模型 | 投影(Part I) | 模式(Part II) | KV Cache 效果 |
|---|---|---|---|
| LLaMA 3.x / Qwen 3 | GQA | Full Attention | ~4x 宽度压缩 |
| DeepSeek V3 / R1 | MLA | Full Attention | ~57x 宽度压缩 |
| Kimi K2.6 | MLA | Full Attention | ~57x 宽度压缩 |
| MiMo V2 Flash | GQA | Hybrid SWA+GA (5:1) | ~4x 宽 × ~6x 长 |
| MiMo V2 Pro | GQA | Hybrid SWA+GA (7:1) | ~4x 宽 × ~8x 长 |
| GLM-5.1 | 标准 | DSA (top-) | FLOPs ,存储不变 |
| DeepSeek V4 | MLA | DSA | ~57x 宽 × 长 |
DeepSeek V4 是目前唯一同时压缩两个维度的产品模型。MiMo V2 不用 MLA,完全靠序列维度裁剪。GLM-5.1 的 DSA 不减存储但大幅降低计算 FLOPs。Kimi K2.6 坚守 MLA + Full Attention,将效率问题交给工程优化。2023 年 GQA 大一统的局面已经终结——2026 年的前沿模型在两条轴上做出了截然不同的组合选择。
结语
投影维度的演进:
注意力模式的演进:
两条线独立发展,正交叠加。当它们在 DeepSeek V4 中首次完整交汇——MLA 将每个 token 的 KV 压缩 57 倍,DSA 再将每次需要读取的 token 数从 降到 ——Attention 的效率边界被同时从两个方向推进了一大步。
而 MiniMax 从线性注意力回退到 softmax 的工业教训提醒我们:在这场优化中,唯一不能妥协的是 attention 的表达力。所有成功的方案——MLA 的低秩投影、SWA 的局部窗口、DSA 的动态选择——都保留了 softmax attention 的精确计算,只是在”对哪些 token”和”用多少维度”上做文章。这或许是九年演进给出的最重要启示。
参考文献
- Vaswani, A., et al. “Attention Is All You Need.” NeurIPS 2017. arXiv:1706.03762
- Shazeer, N. “Fast Transformer Decoding: One Write-Head is All You Need.” 2019. arXiv:1911.02150
- Ainslie, J., et al. “GQA: Training Generalized Multi-Query Attention from Multi-Head Checkpoints.” EMNLP 2023. arXiv:2305.13245
- DeepSeek-AI. “DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model.” 2024. arXiv:2405.04434
- Ye, Z., et al. “Differential Transformer.” 2024. arXiv:2410.05258
- DeepSeek & PKU. “NSA: Hardware-Aligned and Natively Trainable Sparse Attention.” ACL 2025 Best Paper. arXiv:2502.11089
- Dao, T., et al. “FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness.” NeurIPS 2022. arXiv:2205.14135
- Chen, Z., et al. “MiMo-V2-Flash Technical Report.” 2026. arXiv:2601.02780
- Zhipu AI. “GLM-5 Technical Report.” 2026.
- Moonshot AI. “Kimi K2.” 2025. github.com/moonshotai/Kimi-K2
- DeepSeek-AI. “DeepSeek-V4: A Preview.” 2026. api-docs.deepseek.com